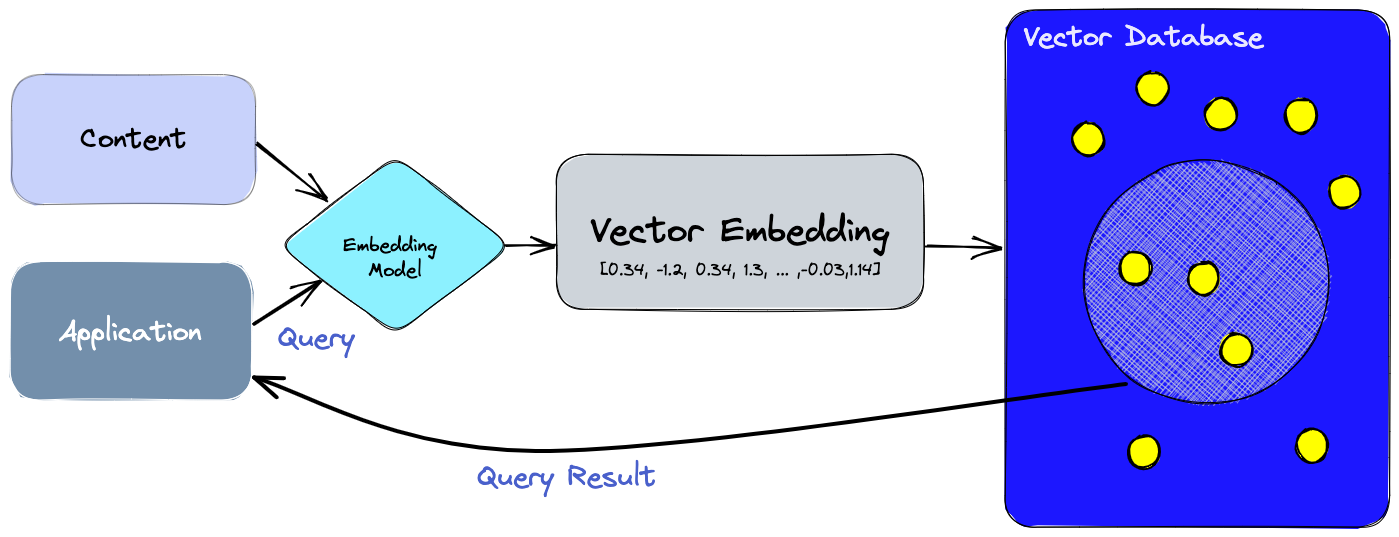
벡터 데이터베이스: Vector Database란?

Vector databases는 데이터 저장 및 조회에 벡터 연산을 활용하는 현대적인 데이터베이스 시스템입니다. 기존의 데이터베이스가 텍스트나 숫자와 같은 원시 데이터 형태를 주로 다루는 반면, 벡터 데이터베이스는 데이터를 고차원 벡터로 표현하고, 이를 활용하여 더욱 효과적인 검색 및 분석을 제공합니다.
1. 벡터란 무엇인가?
벡터는 크기와 방향을 갖는 양으로, 여러 분야에서 중요한 개념으로 사용됩니다. 특히, 머신 러닝과 데이터 과학에서는 고차원 벡터로 데이터를 표현하는 것이 일반적입니다.
1.1. 벡터의 기본
벡터는 방향과 크기를 가진 양입니다. 예를 들어, 물리학에서는 속도나 힘을 벡터로 표현합니다.
# Python에서의 벡터 표현
vector = [2, 3]
1.2. 고차원 벡터
데이터 과학에서, 고차원의 벡터는 여러 특성이나 차원을 가진 데이터를 표현하는 데 사용됩니다. 예를 들어, 이미지나 텍스트 데이터는 수천에서 수백만의 차원을 가질 수 있습니다.
# 고차원 벡터의 예
high_dimensional_vector = [0.2, 0.4, 0.5, ..., 0.1]
2. Vector Database의 동작 원리
전통적인 데이터베이스는 우리가 잘 알고 있는 방식으로 동작합니다. 주로 텍스트, 숫자와 같은 스칼라 데이터를 행과 열에 저장합니다. 그러나 벡터 데이터베이스는 벡터를 중심으로 동작하기 때문에, 최적화 방식과 쿼리 방식이 전혀 다릅니다.
2.1. 데이터의 벡터화
데이터가 벡터 데이터베이스에 저장되기 전, 해당 데이터는 고차원 벡터로 변환됩니다. 이 변환 과정은 대개 머신 러닝 알고리즘을 사용하여 수행되며, 변환된 벡터는 원본 데이터의 의미적 연결성을 유지하면서도 더욱 효과적인 검색을 가능하게 합니다.
2.2. 벡터 기반의 데이터 검색
전통적인 데이터베이스에서는 주로 데이터의 값이 쿼리와 정확히 일치하는 행을 검색합니다. 그러나 벡터 데이터베이스에서는 유사도 메트릭을 적용하여 우리의 쿼리와 가장 유사한 벡터를 찾습니다. 이때 사용되는 주요 알고리즘은 근사 최근접 이웃(Approximate Nearest Neighbor, ANN) 검색을 위한 것입니다. 이러한 알고리즘은 해싱, 양자화, 그래프 기반 검색 등을 통해 검색을 최적화합니다.
2.3. Vector Database 파이프라인

- 인덱싱: 벡터 데이터베이스는 PQ, LSH, HNSW와 같은 알고리즘을 사용하여 벡터를 인덱싱합니다. 이 단계에서 벡터는 빠른 검색을 가능하게 하는 데이터 구조로 매핑됩니다.
- 쿼리: 벡터 데이터베이스는 인덱싱된 쿼리 벡터와 데이터셋 내의 인덱싱된 벡터를 비교하여 최근접 이웃을 찾습니다. 여기서 사용되는 유사도 메트릭은 해당 인덱스에 따라 다를 수 있습니다.
- 후처리: 경우에 따라, 벡터 데이터베이스는 데이터셋에서 최종 최근접 이웃을 검색하여 후처리를 수행하고 최종 결과를 반환합니다. 이 단계는 다른 유사도 측정법을 사용하여 최근접 이웃을 재정렬하는 것을 포함할 수 있습니다.
3. Vector Database의 장점
벡터 데이터베이스는 전통적인 데이터베이스와는 다르게 설계되었기 때문에, 여러 독특한 장점을 가지고 있습니다.
3.1. 복잡한 데이터 형식에 대한 탁월한 성능
벡터 데이터베이스는 이미지, 텍스트, 음성과 같은 복잡한 데이터 형식을 효과적으로 처리할 수 있습니다. 전통적인 데이터베이스에서는 이런 데이터 형식의 처리가 어려울 수 있는데, 벡터 데이터베이스는 이를 위해 특별히 최적화되어 있습니다.
3.2. 유사도 검색의 우수성
전통적인 데이터베이스는 정확한 일치를 기반으로 검색을 수행하는 반면, 벡터 데이터베이스는 유사도 기반의 검색을 제공합니다. 이로 인해 사용자는 훨씬 더 관련성 높은 결과를 빠르게 얻을 수 있습니다. 이것은 추천 시스템, 이미지 인식, 음성 인식 등 다양한 애플리케이션에서 큰 장점으로 작용합니다.
마치며
함께 읽으면 좋은 글


참고 문헌